Lorenzo Bettini is an Associate Professor in Computer Science at the Dipartimento di Statistica, Informatica, Applicazioni "Giuseppe Parenti", Università di Firenze, Italy. Previously, he was a researcher in Computer Science at Dipartimento di Informatica, Università di Torino, Italy.
He has a Masters Degree summa cum laude in Computer Science (Università di Firenze) and a PhD in "Logics and Theoretical Computer Science" (Università di Siena).
His research interests cover design, theory, and the implementation of statically typed programming languages and Domain Specific Languages.
He is also the author of about 90 research papers published in international conferences and international journals.
I tried the KDE Plasma 6 (beta) by using the KDE Neon Unstable Edition.
This is a quick report.
I tried that in a KVM virtual machine. I had to disable 3d graphics, or the installer showed an empty Window.
Here’s the live environment where I started the installer:
Note that it uses the Wayland session by default:
There are not many options when choosing to erase the disk:
The installation went smoothly.
Upon reboot, the login screen allows you to choose the X11 session, but Wayland is the default (that’s what I used):
Without 3D, you miss the blur and other effects; for example, you only get transparency without blurring:
Let’s enable 3D (“Display Spice”, “Listen Type = None” and check “OpenGL”, “Apply”, and then “Video Virtio”, check “3D acceleration”).
Everything seems to work this time (so the problem was only during the installation). We now have blur effects and smooth 3D effects:
The “Overview” effect (Alt+W) looks much nicer now (in the meantime, I switched to the dark theme), and it retains the features I had already blogged about:
The default Task Switcher (Thumbnail Grid) now makes sense (in Plasma 5, changing the default Task Switcher was the first thing I was doing in Plasma 5!):
From the visual point of view, you now also have a floating panel enabled by default.
There was a substantial system update (about 500Mb), which I applied. After rebooting, I was greeted like this:
Unfortunately, the links do not work: no browser opens…
After the update, logging out does not seem to work anymore: I get a blank screen. The same holds for the other menus like “Shut Down” and “Restart”. Welcome to beta software 😉
However, I did another upgrade the day after, and these issues were fixed.
By the way, if you want to upgrade the system, remember that in KDE Neon, you should not use “sudo apt upgrade” but “sudo pkcon update“.
These are the system information (remember: I’m on a virtual machine):
Speaking about desktop effects, we have the (useless but good-looking) Desktop Cube back! You have to enable it in the “Desktop Effects” and remember you must have at least 4 virtual desktops, or the effect will not kick in:
Cool effect 🙂
Speaking of the Desktop effects, the other effects seem to work fine, at least the ones I tried: Present Windows, Magic Lamp, Cover Flow (task switcher), and Blur.
In Wayland, there are some small quirks. The one I noted most is the missing close/maximize/minimize icons in Firefox (you cannot see them, though if you hover, you can press them):
This is a quick post about having nice fonts in Eclipse in Windows 11, based on my experience (maybe I had bad luck with the default configurations of Eclipse and/or Windows).
When I bought my Acer Aspire Vero, I found Windows 11 installed, and now and then, I’m using Windows 11 (though I’m using Linux most of the time). As an Eclipse user, I immediately installed Eclipse. However, I found the default fonts were really ugly:
Indeed, “Courier New” is not the most beautiful mono-space font 😉
Other applications look nice in Windows 11, including text editors. They use, by default, “Lucida Console”, which looks OK:
Indeed, Eclipse uses “Consolas” for other Text parts:
“Consolas” looks even better than “Lucida”! I changed that in Eclipse also for the standard Text font, and the result looks nice to me:
I have already blogged about Gitpod, which allows you to spin up fresh development environments from your GitHub projects so that you can code with Visual Studio on the web (that’s just a very reductive definition, so you may want to look at its website for the complete set of features). I have already shown how to use it for Ansible and Molecule.
Today, I will show how to use Gitpod for Java/Maven projects. This is the first post of a series about Java, Maven, and Gitpod.
NOTE: Although the post focuses on Gitpod, most of the features we will see come from Visual Studio Code and the extensions we will install. Thus, the same mechanisms could be used also on a locally installed Visual Studio Code. In that respect, it is best to get familiar with the main keyboard shortcuts (these will be shown in Visual Studio Code when no editor is opened):
Gitpod provides an example for Java, but it relies on Spring Boot and is probably too complex, especially if you’re not interested in web applications.
In this post, instead, I’ll start with a very basic Java/Maven project. It is intended as a tutorial, so you might want to follow along doing these steps with your GitHub account.
I start by creating a Maven project with the quickstart archetype locally on my computer:
Now, I can start Gitpod for this repository using the button (as I said, you need to use a browser extension; otherwise, you have to prefix the URL appropriately):
Let’s press the “Gitpod” button. (The first time you use Gitpod, you’ll have to accept a few authorizations.).
Press the “Continue with GitHub” button and wait for the workspace to be ready.
NOTE: I’m using the light theme of Visual Studio in Gitpod in this blog post.
Gitpod detected that this was a Maven project and automatically executed the command:
1
mvn install-DskipTests=false
Note that it also created the file “.gitpod.yml”, which we’ll later tweak to customize the default command and other things:
Moreover, it offers to install the Java extension pack:
Of course, we accept it because we want to have a fully-fledged Java IDE (this is based on the Eclipse JDT Language Server Protocol; you might want to have a look at what a Language Server Protocol, LSP, is). We use the arrow to choose “Install Do not Sync” (we don’t want that in all Gitpod workspaces, and we’ll configure the extensions for this project later).
Once that’s installed (note also the recommended extension GitLens, which we might want to install later, let’s use the gear icon to add the extension to our “.gitpod.yml” so that the extension will be automatically installed and available the next time we open Gitpod on this project:
Unfortunately, the “.gitpod.yml” is a bit messed up now (maybe a bug?), and we have to adjust it so that it looks like as follows:
There’s also a warning on top of the file; by hovering, we can see a few warnings complaining that the transitive dependencies of the extension are not part of the file:
Let’s click on “Quick Fix…” and then apply the suggestions to add the extensions to the file (these are just warnings, but I prefer not to have warnings in my development environment):
In the end, the file should look like this:
YAML
1
2
3
4
5
6
7
8
9
10
11
tasks:
- init: mvn install -DskipTests=false
vscode:
extensions:
-vscjava.vscode-java-pack
-redhat.java
-vscjava.vscode-java-debug
-vscjava.vscode-java-dependency
-vscjava.vscode-java-test
-vscjava.vscode-maven
Note that we have “code lens” in the editor, and we can choose to let Gitpod validate this configuration:
TIP: another extension I always add is “eamodio.gitlens”.
This will rebuild the Docker image for our workspace (see the terminal view at the bottom):
This operation takes some time to complete, so you might want to avoid that for the moment. If you choose to do the operation, in the end, another browser tab will be opened with this new configuration. We can switch to the new browser tab (the “.gitpod.yml” is available in the new workspace, though we still haven’t committed that).
NOTE: I find “mvn install” an anti-pattern, and, especially in this context, it makes no sense to run the “install” phase and run the tests when the workspace starts. In fact, I changed the “init” task to a simpler “mvn test-compile”; this is enough to let Maven resolve the compile and test dependencies when the workspace starts. The Java LSP will not have to resolve them again and will find them in the local Maven cache.
We can take the chance to commit the file by using the corresponding tab in Visual Studio Code and then push it to GitHub (“Sync Changes”):
We could also close the Gitpod tabs and re-open Gitpod (the “.gitpod.yml” is now saved in the GitHub repository), but let’s continue on the open workspace.
Let’s now open a Java file in our project:
We get a notification that the IDE is loading the Java project (this might take a few seconds).
TIP: to quickly open a file knowing (part of) its name, press “Ctrl + P” (see the shortcuts above) and start typing:
We have a fully-fledged Java IDE with “code lens” for running/debugging and parameter names (see the argument passed to “System.out.println”):
For example, let’s use “Run” to run the application and see the output in the terminal view:
Though this project generated by the archetype is just a starting point, we also have a simple JUnit test. Let’s open it.
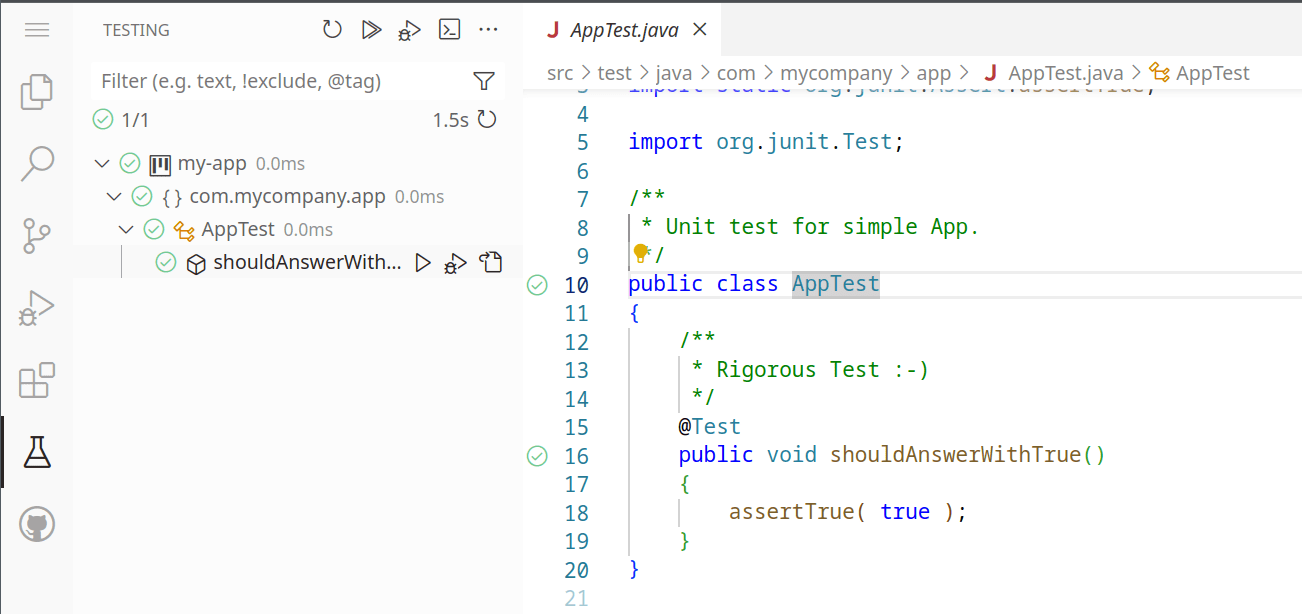
After a few seconds, the editor is decorated with some “code lens” that allows us to run all the tests or a single test (see the green arrow in the editor’s left ruler). Clicking on the arrow immediately runs the tests or a single test. Right-clicking on such arrows gives us more options, like debugging the test.
On the right pane, we can select the “Testing” tab (depicted as a chemical ampoule) that shows all the tests detected in the project (in this simple example, there’s a single one, but in more complex projects, we can see all the tests). We can run/debug them from there.
Let’s run them and see the results (in this case, it is a complete success); note the decorations showing the succeeded tests (in case of failures, the decorations will be different):
Of course, we could run the tests through Maven in the console, but this would be a more manual process, and the output would be harder to interpret in case of failures: we want to use an IDE to run the tests.
We could also run the tests by pressing “F1” and typing “Run tests” (we’ll then use the command “Java: Run Tests”): we need to do that when a JUnit test case is open in the editor.
Let’s hover on the “assertTrue”, which is a static method of the JUnit library. The IDE will resolve its Javadoc and will show it on a pop-up (the “code lens” for the parameter names is also updated):
We can use the menu “Go to definition” (or Ctrl+click) to jump to our project’s source code and libraries. For example, let’s do that on “assertTrue”. We can view the method’s source code in the class “Assert” of JUnit (note that this editor is read-only, and the name of the file ends with “.class”):
Note that the “JAVA PROJECTS” in the “Explorer” shows the corresponding file. In this case, it is a file in the referred test dependency “junit-4.11.jar” in the local Maven cache (see the POM where this dependency is explicit).
Of course, we have code completion by pressing “Ctrl+Space”; when the suggestions appear, we can start typing to filter them, and substring filtering works as well (see the screenshot below where typing “asE” shows completions matching):
With ENTER, we select the proposal. In this case, if we select one “assertEquals”, which is a static method of “Assert”, upon selection, we will also have the corresponding static import automatically added to the file.
That’s all for the first post! Stay tuned for more posts on Java, Maven, and Gitpod! 🙂
This blog post will describe my Ansible role for installing the KDE Plasma desktop environment with several programs and configurations. As for the other roles I’ve blogged about, this one is tested with Molecule and Docker and can be developed with Gitpod (see the linked posts above). In particular, it is tested in Arch, Ubuntu, and Fedora.
This role is for my personal installation and configuration and is not meant to be reusable.
The role assumes that at least the basic KDE DE is already installed in the Linux distribution. The role then installs several programs I’m using daily and performs a few configurations (it also installs a few extensions I use).
At the time of writing, the role has the following directory structure, which is standard for Ansible roles tested with Molecule.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
├── defaults
│ └── main.yml
├── files
│ ├── kde-ssh
│ │ ├── askpass.sh
│ │ ├── ssh-add.desktop
│ │ ├── ssh-agent-shutdown.sh
│ │ └── ssh-agent-startup.sh
│ └── konsole
│ ├── AplumaDark.colorscheme
│ ├── Apricot.colorscheme
│ ├── Apricot.profile
│ ├── Aritim Dark.colorscheme
│ ├── Aritim Dark.profile
│ ├── BlackOnWhite.profile
│ ├── Edna.colorscheme
│ ├── Edna.profile
│ ├── GreenOnBlack.profile
│ ├── Nordic.colorscheme
│ ├── Nordic.profile
│ └── XeroLinux.profile
├── handlers
│ └── main.yml
├── LICENSE
├── meta
│ └── main.yml
├── molecule
│ ├── default
│ │ ├── molecule.yml
│ │ └── prepare.yml
│ ├── fedora
│ │ └── molecule.yml
│ ├── shared
│ │ ├── converge.yml
│ │ └── verify.yml
│ └── ubuntu
│ ├── molecule.yml
│ └── prepare.yml
├── pip
│ └── requirements.txt
├── README.md
├── requirements.yml
├── tasks
│ └── main.yml
├── templates
├── tests
│ ├── inventory
│ └── test.yml
└── vars
└── main.yml
The role has a few requirements, listed in “requirements.yml”:
YAML
1
2
3
---
collections:
- name: community.general
These requirements must also be present in playbooks using this role; my playbooks (which I’ll write about in future articles) have such dependencies in the requirements.
Let’s have a look at the main file “tasks/main.yml”, which is quite long, so I’ll show its parts and comment on the relevant parts gradually.
- name: Override spectacle package name for Ubuntu.
ansible.builtin.set_fact:
kde_spectacle: kde-spectacle
when: ansible_os_family == 'Debian'
- name: Override kvantum package name for Ubuntu.
ansible.builtin.set_fact:
kvantum: qt5-style-kvantum
when: ansible_os_family == 'Debian'
- name: Install Kde Packages
become: true
ansible.builtin.package:
state: present
name:
- kate
- "{{kde_spectacle}}"
- ark
- konsole
- dolphin
- okular
- gwenview
- yakuake
- korganizer
- kaddressbook
- kdepim-addons
- kio-gdrive
- dolphin-plugins
- plasma-systemmonitor
- kcalc
- plasma-workspace-wallpapers
- "{{kvantum}}"
# - latte-dock # it's not maintained anymore
# In Ubuntu doesn't seem to be there
# maybe it's not needed
- name: Install Kde Addons
become: true
ansible.builtin.package:
state: present
name:
-kdeplasma-addons
when: ansible_os_family != 'Debian'
This shows a few debugging details about the current Linux distribution. Indeed, the whole role has conditional tasks and variables depending on the current Linux distribution.
The file installs a few KDE programs I’m using in KDE.
The “vars/main.yml” only defines a few default variables used above:
YAML
1
2
3
4
---
# vars file for my_kde_role
kde_spectacle: spectacle
kvantum: kvantum
As seen above, a few packages have a different name in Ubuntu (Debian), which is overridden.
Then, I configure a few things in the KDE configuration (.ini) files and set a few keyboard shortcuts. The configuration should be self-explanatory.
Then, I ensure Kate is the default editor for textual files (including XML files, which otherwise, would be opened with the default browser); I also configure a few Kate preferences:
YAML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# In Fedora it's not installed by default
- name: Ensure xdg-mime is available
become: true
ansible.builtin.package:
state: present
name:
-xdg-utils
when: ansible_os_family == 'RedHat'
- name: Ensure xdg mime default application is set
Then, I copy a few Konsole profiles (and the corresponding color schemes, see the directory “files/konsole”) and also configure the Yakuake drop-down terminal:
The final part deals with configuring the Kwallet manager to store SSH key passphrases, which, in KDE, has always been a pain to get correctly (at least, now, I have a configuration that I know works on all the distributions mentioned above):
YAML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
- name: Install kwalletmanager and ksshaskpass
become: true
ansible.builtin.package:
state: present
name:
-kwalletmanager
-ksshaskpass
- name: Create autostart directory
ansible.builtin.file:
path: '~/.config/autostart'
mode: 0755
state: directory
- name: Copy ssh-add.desktop
ansible.builtin.copy:
src: "kde-ssh/ssh-add.desktop"
dest: "~/.config/autostart/"
mode: 0644
# inspired by AUR package plasma-workspace-agent-ssh
Concerning Molecule, I have several scenarios. As I said, I tested this role in Arch, Ubuntu, and Fedora, so I have a scenario for each operating system. The “default” scenario is Arch, which nowadays is my daily driver.
The reason for this is explained in my previous posts on Ansible and Molecule.
I have a similar “prepare.yml” for the default scenario, Arch.
I have nothing to verify for this role in the “verify.yml”. I just want to ensure that the Ansible role can be run (and is idempotent) in Arch, Ubuntu, and Fedora.
Of course, this is tested on GitHub Actions and can be developed directly on the web IDE Gitpod.
I hope you find this post useful for inspiration on how to use Ansible to automatize your Linux installations 🙂
Nowadays, I mostly use Arch-based distributions (especially with EndeavourOS). So I haven’t been using Ubuntu for a while and decided to try it again now that the brand new release, 23.10 “Mantic Minotaur”, is available.
Let’s start the installation. This new version of Ubuntu features a new installer, which looks nice. I still feel comfortable with this new installer having already installed Ubuntu many times.
The initial steps are the language, keyboard, and network connection:
In the next step, the installer detected a new version available to download. I said yes. Then, you have to restart the installer, starting from scratch.
By default, Ubuntu proposes a minimal installation when choosing the installation type. However, I prefer to have most of the things installed during this stage, so I chose the “Full Installation”:
Then, we get to the partitioning. As usual, I prefer manual partitioning since I have several Linux distributions installed on my computer. I chose EXT4 as the file system. On Arch, I use BTRFS. However, Ubuntu does not come with good defaults for BTRFS. I dealt with such problems in the past, but now I prefer to stick with EXT4 in Ubuntu and give up on BTRFS snapshots.
Then, we get to the timezone selection (the installer automatically detected my location) and user details. This is as usual.
Interestingly, you can select during the installation the theme and the color accent (that’s nothing special, but it is a nice surprise):
The installation starts; by clicking on the small icon on the bottom right, you can also enable logging on the terminal:
The installation only took a few minutes on this laptop.
Time to restart. Of course, at the first login, you get some updates to install:
The touchpad is already configured with tap-to-click, but it defaults to “natural scrolling” (which I don’t like). That gave me the chance to see the new nice-looking Gnome setting for the touchpad:
I installed Dropbox, and with the Ubuntu extension for “app indicator”, the Dropbox icon appears in the tray bar. It works (mostly: sometimes it always shows as if it is synchronizing, though everything is up-to-date).
Remember that the current icon theme does not show the “Dropbox” folder in Nautilus with overlay.
Connecting an external HDMI monitor works perfectly (so Wayland is not a problem); I prefer to mirror the contents:
Also, GNOME extensions work fine. Despite the new GNOME Version (45), known to have broken all extensions due to an API breakage, the ones I use seem to have been ported and work correctly.
I don’t like the fact that, despite a SWAP partition already present on my disk, the installer did not pick it up: the result is the usage of a small SWAP file, which I don’t like.
1
.rw-------4.3Groot4Nov18:06swap.img
I removed this line from the “/etc/fstab”:
1
/swap.img none swap sw00
I added the line to refer to my existing SWAP partition.
I also enabled ZRAM, which will automatically have precedence over the SWAP partition:
1
2
sudo apt install systemd-zram-generator
sudo systemctl daemon-reload
1
2
3
4
❯swapon
NAME TYPE SIZE USED PRIO
/dev/nvme0n1p4 partition21G2M-2
/dev/zram0 partition4G0B100
I don’t like the wallpapers shipped with this version (in the screenshot, you can easily tell the GNOME wallpapers from the Ubuntu ones):
However, I typically use Variety for wallpapers, so it’s not a big problem.
IMPORTANT: as I have already blogged, you need additional fonts for “Oh-My-Zsh” with the “p10k” prompt.
All in all, Ubuntu 23.10 seems pretty stable and smooth. I’m using it (not as my daily driver), and for the moment, I’m enjoying it.
Here’s another post on how to get started with Hyprland.
This time, we’ll see how to configure notifications with mako, a lightweight notification daemon for Wayland, which also works with Hyprland. (you might also want to consider and experiment with an alternative: dunst).
If you followed my previous tutorials, you have no notification daemon installed. You can verify that by running the following command (to issue a notification manually) and by looking at the resulting errors:
1
2
$ notify-send "hello"
GDBus.Error:org.freedesktop.DBus.Error.ServiceUnknown: The name org.freedesktop.Notifications was not provided by any .service files
Let’s install “mako”:
1
sudo pacman-Smako
The nice thing about mako is that you don’t need to start it as a service manually: the first time a notification is emitted, mako will run automatically.
Let’s try to run the above notification command above, and this time, we see the pop-up, by default, on the right top corner of the screen:
You have to click the pop-up to make it disappear.
Each time a program emits a notification, mako will show it. For example, Thunderbird, Firefox, and Chrome will emit notifications that mako will display.
Let’s do some further experiments by manually emitting notifications:
1
notify-send"hello world\!""This is a message"
will lead to
You can see that the first argument is the title and formatted in boldface.
You can have a look at mako’s manual (5) about its configuration file and where it is searched for:
1
2
3
4
5
6
7
8
9
10
11
12
man 5 mako
NAME
mako - configuration file
DESCRIPTION
The config file is located at <strong>~/.config/mako/config</strong> or at $XDG_CON‐
FIG_HOME/mako/config. Option lines can be specified to configure mako like so:
key=value
Empty lines and lines that begin with # are ignored.
Each time you modify the configuration, you must reload mako by using one of the following commands:
1
killall mako
or
1
makoctl reload
With that example configuration, we can emit a few notifications with different “urgencies”, and see the different colors and positions of the boxes:
1
2
3
4
5
6
7
notify-send-ulow"hello world\!""This is a low urgency message"
notify-send-unormal"hello world\!""This is a normal message"
notify-send-ucritical\
"This is a critical message\!"\
"OK, that was just a demo ;)"
If you use EndeavourOS, you will get notifications about new updates and when a reboot is required after a system update (the latter is a “critical” notification):
This blog post will describe my Ansible role for installing the GNOME desktop environment with several programs and configurations. As for the other roles I’ve blogged about, this one is tested with Molecule and Docker and can be developed with Gitpod (see the linked posts above). In particular, it is tested in Arch, Ubuntu, and Fedora.
This role is for my personal installation and configuration and is not meant to be reusable.
The role assumes that at least the basic GNOME DE is already installed in the Linux distribution. The role then installs several programs I’m using on a daily basis and performs a few configurations (it also installs a few extensions I use).
At the time of writing, the role has the following directory structure, which is standard for Ansible roles tested with Molecule.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
├── defaults
│ └── main.yml
├── files
├── handlers
│ └── main.yml
├── LICENSE
├── meta
│ └── main.yml
├── molecule
│ ├── default
│ │ ├── molecule.yml
│ │ └── prepare.yml
│ ├── fedora
│ │ └── molecule.yml
│ ├── no-flatpak
│ │ ├── converge.yml
│ │ ├── molecule.yml
│ │ └── verify.yml
│ ├── shared
│ │ ├── converge.yml
│ │ └── verify.yml
│ └── ubuntu
│ ├── molecule.yml
│ └── prepare.yml
├── pip
│ └── requirements.txt
├── README.md
├── requirements.yml
├── tasks
│ ├── flatpak.yml
│ ├── gnome-arch.yml
│ ├── gnome-configurations.yml
│ ├── gnome-extension-manager.yml
│ ├── gnome-extensions.yml
│ ├── gnome-templates.yml
│ ├── gnome-tracker.yml
│ ├── guake.yml
│ └── main.yml
├── templates
├── tests
│ ├── inventory
│ └── test.yml
└── vars
└── main.yml
The role has a few requirements, listed in “requirements.yml”:
YAML
1
2
3
4
5
6
7
---
roles:
- name: petermosmans.customize-gnome
version: 0.2.10
collections:
- name: community.general
These requirements must also be present in playbooks using this role; my playbooks (which I’ll write about in future articles) have such dependencies in the requirements.
This shows a few debug information about the current Linux distribution. Indeed, the whole role has conditional tasks and variables depending on the current Linux distribution.
The file installs a few programs, mainly Gnome programs, but also other programs I’m using in GNOME.
The “vars/main.yml” only defines a few default variables used above:
YAML
1
2
3
4
---
# vars file for my_gnome_role
python_psutil: python3-psutil
with_flatpak: true
As seen above, the package for “python psutils” has a different name in Arch, and it is overridden.
For Arch, we have to install a few additional packages, which are not required in the other distributions (file “gnome-arch.yml”):
YAML
1
2
3
4
5
6
7
8
9
10
11
12
13
---
- name: Install Gnome Packages (Arch Linux)
become: true
ansible.builtin.package:
state: present
name:
-gvfs-afc
-gvfs-goa
-gvfs-google
-gvfs-gphoto2
-gvfs-mtp
-gvfs-nfs
-gvfs-smb
For the Guake dropdown terminal, we install it (see the corresponding YAML file).
The file “gnome-templates.yml” creates the template for “New File”, which, otherwise, would not be available in recent versions of GNOME, at least in the distributions I’m using.
YAML
1
2
3
4
5
6
7
8
9
10
11
- name: Create Templates directory
ansible.builtin.file:
path: '~/Templates'
state: directory
mode: 0755
- name: Create Templates
ansible.builtin.copy:
content: ""
dest: '~/Templates/New File'
mode: 0644
For the search engine GNOME Tracker, I performed a few configurations concerning the exclusion mechanisms. This is done by using the Community “dconf” module:
YAML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# the default was ['.trackerignore', '.git', '.hg', '.nomedia']
# but that way the contents of a git working directory are not indexed
- name: Customize Tracker Ignored directories with content
- name: Make sure Tracker 2 is NOT installed (Arch)
become: true
ansible.builtin.package:
state: absent
name:
- tracker
- tracker-miners
when: ansible_os_family == 'Archlinux'
# In previous versions of ubuntu the service file was
# tracker-extract.service
# In more recent versions is
# tracker-extract-3.service
- name: Disable Tracker Extract at system level
ansible.builtin.systemd:
name: tracker-extract-3
scope: global
masked: yes
# Better to mask it at the global level
# so that it can be run also in a chroot environment
# otherwise we get "Failedtoconnecttobus: No such file or directory"
This also ensures that possibly previous versions of Tracker are not installed. Moreover, while I use Tracker to quickly look for files (e.g., with the GNOME Activities search bar), I don’t want to use “Tracker extract”, which also indexes file contents. For indexing file contents, I prefer “Recoll”, which is installed and configured in my dedicated playbooks for specific Linux distributions (I’ll blog about them in the future).
Then, the file “gnome-configurations.yml” configures a few aspects (the comments should be self-documented), including some custom keyboard shortcuts (including the one for Guake, which, in Wayland, must be set explicitly as a GNOME shortcut):
Then, by using the “petermosmans.customize-gnome” role (see the requirements file above), I install a few GNOME extensions, which are specified by their identifiers (these can be found on the GNOME extensions website). I leave a few of them commented out, since I don’t use them anymore, but I might need them in the future):
YAML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
# Required for unzipping extension archives
- name: Install Unzip
become: true
ansible.builtin.package:
state: present
name:
-unzip
# Downloading extensions is very flaky, so if it succeeds on 'converge'
# we skip it on 'idempotence'
- name: Install Gnome Extensions
ansible.builtin.include_role:
name: petermosmans.customize-gnome
tags: molecule-idempotence-notest
vars:
gnome_extensions:
- id: 19 # User Theme "user-theme@gnome-shell-extensions.gcampax.github.com"
- id: 615 # AppIndicator and KStatusNotifierItem Support
# To remove the filters on flathub introduced by Fedora
# see https://ask.fedoraproject.org/t/ansible-flathub-repo-setup/19176
# see https://fedoraproject.org/wiki/Changes/Filtered_Flathub_Applications
- name: Remove filters from flathub
become: true
ansible.builtin.command:
cmd: flatpak remote-modify --no-filter flathub
changed_when: false
YAML
1
2
3
4
5
6
- name: Install Gnome Extension Manager
become: true
community.general.flatpak:
name: com.mattjakeman.ExtensionManager
state: present
# method: user
I installed them system-wide (the “user” option is commented out).
Concerning Molecule, I have several scenarios. As I said, I tested this role in Arch, Ubuntu, and Fedora, so I have a scenario for each operating system. The “default” scenario is Arch, which nowadays is my daily driver.
However, after running the playbook and restarting, the terminal did not look quite right:
You see the OS logo before the “>” is not displayed, and other icon fonts (I’m using exa/eza instead of “ls”) are missing, too (e.g., the one for YAML and Markdown files). In Arch, I knew how to solve icon problems for exa. Here in Ubuntu, I never experimented in that respect.
However, the p10k GitHub repository provides many hints in that respect. Unfortunately, Ubuntu does not provide packages for Nerd fonts. However, the p10k GitHub repository provides some Meslo fonts that can be directly downloaded.
The commands to solve the problem (provided you already have “fontconfig” and “wget” installed, otherwise, do install them) are:
Now, reboot (this seems to be required), and the next time you open the terminal, everything looks fine (note the OS icon and the icons for YAML and Markdown files):
Of course, you could also download another Nerd font from the corresponding GitHub repository, but this procedure seems to work like a charm, and you use the p10k recommended font (Meslo).
By the way, the Gnome Text Editor automatically uses the new icon fonts. Other programs like Kate (which I use in Gnome as well) have to be configured to use the Meslo font.
I am writing this report about my (nice) experience upgrading the SSD (1 TB) to my Dell OptiPlex 5040 MiniTower. That’s an old computer (I bought it in 2016), but it’s still working great. However, its default SSD of 256 GB was becoming too small for Windows and my Linux distributions. This computer also came with a secondary mechanical hard disk (1 TB).
DISCLAIMER: This is NOT meant to be a tutorial; it’s just a report. You will do that at your own risk if you perform these operations! Ensure you did not void the warranty by opening your laptop.
I wrote this blog post as a reminder for myself in case I have to open this desktop again in the future!
To be honest, my plan was to add the new SSD as an additional SSD, but, as described later, I found out that the mechanical hard disk was a 2.5 one, so I replaced the old SSD with the new one (after cloning it). I’ve used a “FIDECO YPZ220C” to perform the offline cloning, which worked great!
This is the BIOS status BEFORE the upgrade:
I seem to remember that “RAID” is required to have Linux installed on such a machine.
This is the new SSD (a Samsung 870 EVO, 1 TB, SATA 2.5”):
The cool thing about this desktop PC, similar to other Dell computers I had in the past, is that you don’t need a screwdriver: you disassemble it just with your hands. However, I suggest you have a look at a disassembling video like the one I’ve used: https://www.youtube.com/watch?v=gXePa1N_8iI. I know the video is about a Dell Optiplex 7040 MT, while mine is a Dell Optiplex 5040 MT, but their shapes and internals look the same. On the contrary, the Dell Optiplex 5040 SmallFactor videos are not useful because there’s a huge difference between my MiniTower and a SmallFactor 5040.
These are a few photos of the disassembling, showing the handles to use to open the computer, disconnect a few parts, and access the part holding the 2.5 drives.
This is the part holding the two 2.5 drives (as I said, at this point, I realized that also the mechanical hard disk is occupying one such place):
The SSD (I will replace) is the first one on top.
It’s easy to remove that: just use the handles to pull it off:
There are no screws to remove: you just enlarge the container to remove the SSD and insert the new one.
As I said above, I inserted the new one after performing the offline cloning.
Once I closed the desktop, the BIOS confirmed that the new SSD was recognized! 🙂
Now, some bad news (which is easy to fix, though): if you use a partition manager, e.g., in Linux, the SSD is seen as 1 TB, but the partitions are based on the original source SSD, so you end up with lots of free space that you cannot use!
For example, here’s the output of fdisk, which understands there’s something wrong with the partition table:
1
2
3
4
5
6
7
8
9
10
11
❯ sudo fdisk /dev/sda
Welcome to fdisk (util-linux 2.39.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
GPT PMBR size mismatch (500118191 != 1953525167) will be corrected by write.
The backup GPT table is not on the end of the device. This problem will be corrected by write.
This disk is currently in use - repartitioning is probably a bad idea.
It's recommended to umount all file systems, and swapoff all swap
partitions on this disk.
It also suggests that it’s not a good idea to try to fix it when one of the partitions is mounted.
Using a live ISO, e.g., the one from EndeavourOS, is just a matter of fixing the partition table as follows.
1
2
3
4
5
6
7
8
9
10
$ parted -l
Warning: Not all of the space available to /dev/sda appears to be used, you can
fix the GPT to use all of the space (an extra 10485760 blocks) or continue with
the current setting?
Fix/Ignore?
Answer: fix
GPT PMBR Size Mismatch Error Fix
That’s it. Problem fixed you can reboot VM.
Now, you have access to the whole space in the disk.
Up to now, I have shown how to get started with Hyprland with the initial configurations.
Now, I’ll show how to install the mainstream status bar in Hyprland: Waybar. Again, I’m going to do that for Arch Linux. As in the previous posts, I will NOT focus on the look and feel configuration.
Before continuing, the Waybar module for keyboard status (Caps lock and Num lock) requires the user to be part of the “input” group. Ensure your user is part of that group by running “groups”. If not, then add it with
1
sudo usermod-aG input$USER
Then, you must log out and log in.
First of all, the official package waybar already supports Hyprland (in the past, you had to install an AUR package). So, let’s install the main packages (as usual, you might want to make sure your packages are up-to-date before going on):
1
sudo pacman-Swaybar
Let’s open a terminal and start Waybar
1
waybar&
The result is not that good-looking
Waybar heavily relies on Nerd fonts for icons, and, currently, we don’t have any installed (unless you have already installed a few yourself).
The terminal will also be filled with a few warnings about a few missing things (related to Sway) and errors about failures to connect to MPD.
Let’s quit Waybar (close the terminal from where you launched it), and let’s fix the font problem by installing a few font packages:
Let’s start Waybar again, and this time it looks better:
Try to click on the modules and see what happens. For some of them, the information shown will change (e.g., the time will turn into the date).
Let’s quit Waybar again, and let’s start configuring it. We must create the configuration files for Waybar (by default, they are searched for in “~/.config/waybar”). We can do that by using the default ones:
1
2
mkdir-p~/.config/waybar
cp/etc/xdg/waybar/*~/.config/waybar/
The above command will copy “config” (with the configuration of Waybar modules, i.e., the “boxes” shown in the bar; The configuration uses the JSON file format) and style.css (for the style).
Let’s edit “config”. At the time of writing, this is the initial part of the configuration file:
1
2
3
4
5
6
7
8
9
10
11
12
{
// "layer": "top", // Waybar at top layer
// "position": "bottom", // Waybar position (top|bottom|left|right)
"height":30,// Waybar height (to be removed for auto height)
The initial parts specify the position and other main configurations. This part must be enabled:
1
"layer":"top",
Otherwise, Waybar popups render behind the windows
Let’s edit the modules that must be shown on the bar’s left, center, and right. Of course, this is subjective; here, I show a few examples. The modules starting with “sway” are for the Sway Window Manager, while we’re using Hyprland, and we must use the corresponding ones:
Each module, together with its configuration, is documented in the Waybar Wiki.
Let’s focus on the left and center modules. I’ve opened three workspaces, and here’s the result (note the workspace indicator on the left, and on the center, we see the currently focused window’s title, in this case, Firefox):
By editing the “style.css” file, we can change the workspace indicator so that we better highlight the current workspace:
1
2
3
4
#workspaces button.active {
background-color:green;
box-shadow:inset0-3px#ffffff;
}
Restart Waybar, and now the current workspace is well distinguished:
The “tray” module is useful to show applications running in the background, like “skype”, “dropbox,” or the “network-manager-applet”.
Let’s now define a custom module, for example, one for showing a menu for locking the screen, logging out, rebooting, etc. To do that, first, we need to install the AUR package “wlogout”:
1
yay-Swlogout
Let’s say we want to add it as the last module on the right. We edit the Waybar config file like this:
1
"modules-right":...asbefore...,"custom/power"],
Then, in the same file, before closing the last JSON element, we define such a module (remember to add a comma after the previously existing last module):
1
2
3
4
5
6
7
8
...
},
"custom/power":{
"format":" ⏻ ",
"tooltip":false,
"on-click":"wlogout --protocol layer-shell"
}
}
Note that I’ve used a character using the installed Nerd font. Of course, you can choose anything you like. The “wlogout” menu will appear when you click on that module. Let’s restart Waybar and verify that:
By editing the “style.css”, you can customize the style of this custom module, e.g.,
1
2
3
#custom-power {
background-color:#ffa000;
}
When we’re happy with the configuration, we modify the Hyprland configuration file to start Waybar automatically when we enter Hyprland:
1
exec-once=waybar
Restart Hyprland and Waybar will now appear automatically.
Finally, you can have several Waybar bars, i.e., instances, in different parts of the screen, each one with a different configuration.
For example, let’s create another Waybar configuration for showing a Taskbar to show all the running applications from all workspaces. This can be useful to quickly look at all the running applications and quickly switch to any of them, especially in the presence of many workspaces.
I create another configuration file in the “~/.config/waybar” directory, e.g., “config-taskbar”, with these contents (you could also configure several Waybar instances in the same configuration file, but I prefer to have one configuration file for each instance):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
"layer":"top",// Waybar at top layer
"position":"bottom",// Waybar position (top|bottom|left|right)
"height":30,// Waybar height (to be removed for auto height)
// "width": 1280, // Waybar width
"spacing":4,// Gaps between modules (4px)
// Choose the order of the modules
"modules-center":["wlr/taskbar"],
// Modules configuration
"wlr/taskbar":{
"format":"{icon}",
"icon-size":16,
//"icon-theme": "Numix-Circle",
"tooltip-format":"{title}",
"on-click":"activate",
"on-click-middle":"close"
}
}
We can call it from the command line as follows:
1
waybar--config~/.config/waybar/config-taskbar
Here’s the second instance of Waybar on the bottom, showing all the running applications (from all the workspaces):
Unfortunately, in my experience, not all icons for all running applications are correctly shown: for example, for “nemo”, you get an empty icon in the taskbar. You can click it, but visually, you don’t see that… maybe it has something to do with the icon set. I still have to investigate.
You can run both instances when Hyprland starts by putting these two lines in the “hyprland.conf” file:
In this blog post, I will describe a few scenarios where you want to update versions in a multi-module Maven project consistently. In these examples, you have both a parent POM, which is meant to contain common properties and configurations to be inherited throughout the other projects, and aggregator POMs, which are meant to be used only to build the multi-module project. Thus, the parent itself is NOT meant to be used to build the multi-module project.
I’m not saying that such a POM configuration and structure is ideal. I mean that it can be seen as a good practice to separate the concept of parent and aggregator POMs (though, typically, they are implemented in the same POM). However, in complex multi-module projects, you might want to separate them. In particular, as in this example, we can have different separate aggregator POMs because we want to be able to build different sets of children’s projects. The aggregators inherit from the parent to make things a bit more complex and interesting. Again, this is not strictly required, but it allows the aggregators to inherit the shared configurations and properties from the parent. However, this adds a few more (interesting?) problems, which we’ll examine in this article.
Description:
Sets the current project’s version and based on that change propagates that change onto any child modules as necessary.
This is the aggregator1 POM (note that it inherits from the parent and also mentions the parent as a child because we want to build the parent during the reactor, e.g., to deploy it):
[ERROR]Failed toexecute goal org.codehaus.mojo:versions-maven-plugin:2.14.2:set(default-cli)on project example.aggregator1:Project version isinherited from parent.->[Help1]
[ERROR]Non-resolvable parentPOM forcom.examples:example.aggregator1:0.0.1-SNAPSHOT:Could notfind artifact com.examples:example.parent1:pom:0.0.1-SNAPSHOT and'parent.relativePath'points at wrong local POM@line4,column10->[Help2]
[ERROR]
Before going on, let’s revert the change of version in parent1.
Let’s add references to aggregators in parent1
XHTML
1
2
3
4
<modules>
<module>../example.aggregator1</module>
<module>../example.aggregator2</module>
</modules>
Let’s run the Maven command on parent1:
1
[ERROR]Childmodule example.parent1/pom.xml of example.aggregator1/pom.xml forms aggregation cycle example.parent1/pom.xml->example.aggregator1/pom.xml->example.parent1/pom.xml@
That makes sense: the aggregator has the parent as a child, and the parent has the aggregator as a child.
But what if we help Maven a little to detect all the children without a cycle?
It looks like it is enough to “hide” the references to children inside a profile that is NOT activated:
XHTML
1
2
3
4
5
6
7
8
9
10
11
<profiles>
<profile>
<!-- DON'T activate it, it's only to let Maven
detect the the children -->
<id>update-versions-only</id>
<modules>
<module>../example.aggregator1</module>
<module>../example.aggregator2</module>
</modules>
</profile>
</profiles>
And the update works. All the versions are consistently updated in all the Maven modules:
The important thing is that aggregator2 does not have parent1 as a module (just parent2), or the Maven command will not terminate.
We can also consistently update the version of a single artifact; if the artifact is a parent POM, the references to that parent will also be updated in children. For example, let’s update only the version of parent2 by running this command from the parent1 project and verify that the versions are updated consistently:
Unfortunately, this is not the correct result: the version of parent2 has not been updated. Only the references to parent2 in the children have been updated to a new version that will not be found.
For this strategy to work, parent2 must have its version, not the one inherited from parent1.
Let’s verify that: let’s manually change the version of parent2 to the one we have just set in its children:
XHTML
1
2
3
4
5
6
7
8
9
10
<parent>
<groupId>com.examples</groupId>
<artifactId>example.parent1</artifactId>
<version>0.0.2-SNAPSHOT</version>
<relativePath>../example.parent1</relativePath>
</parent>
<artifactId>example.parent2</artifactId>
<packaging>pom</packaging>
<version>0.0.3-SNAPSHOT</version>
And let’s try to update to a new version the parent2:
Let’s try and be more specific by specifying the old version (after all, we’re running this command from parent1 asking to change the version of a specific child):
This time it worked! It updated the version in parent2 and all the children of parent2.
Let’s reset all the versions to the initial state.
Let’s remove the “hack” of child modules from parent1 and create a brand new aggregator that does not inherit from any parent (in fact, it configures the versions plugin itself) but serves purely as an aggregator:
But what if we apply the same trick of the modules inside a profile in this new aggregator project, which is meant to be used only to update versions consistently?
This time, the version update works even when the same module is present in both our aggregator1 and aggregator2! Moreover, versions are updated only once in the module mentioned in both our aggregators:
Maybe, this time, this is not to be considered a hack because we use this aggregator only as a means to keep track of version updates consistently in all the children of our parent POMs.
As I said, these might be seen as complex configurations; however, I think it’s good to experiment with “toy” examples before applying version changes to real-life Maven projects, which might share such complexity.
I am writing this report about my (nice) experience adding a second SSD (an NVMe, 1 Tb) to my LG GRAM 16, my main laptop that I’ve enjoyed for two years.
DISCLAIMER: This is NOT meant to be a tutorial; it’s just a report. You will do that at your own risk if you perform these operations! Ensure you did not void the warranty by opening your laptop.
I wrote this blog post as a reminder for myself in case I have to open the laptop again in the future!
I also decided to describe my experience because there seems to be some confusion and doubts about which kind of SSD you can add in the second slot (SATA? or PCI?). At least for this model, LG GRAM 16 (16Z90P), I could successfully and seamlessly insert an NVMe M.2 PCIe3. This is the SSD I added, Samsung SSD 970 EVO Plus (NOTE: this SSD does NOT include a screw for securing the SSD to the board; however, the LG GRAM has a screw in the second slot, so no problem!):
You can also see the internal of the laptop below and what’s written in the second slot.
These are the tools I’ve used:
It’s time to open the back cover. That’s the first time I did that, and I found it not very easy… not impossible, but not even as easy as I thought. Fortunately, there are several videos that show this procedure. In particular, there’s an “official” one from LG, which I suggest to follow: https://www.youtube.com/watch?v=55gM-r2xtmM.
Removing the rubber feet (there are three types) was not easy from the beginning: they are “sticky”, but with a proper tool (the grey one in the picture above), I managed to remove the bigger ones and the one at the top.
For the other smaller ones, I had to use a cutter. Be careful because they tend to jump on your face (mind your eyes). 😉 Moreover, you have to be careful not to use too much force because you might break the bigger ones (in the linked video, you can see that the person breaks the one in the low left corner)
And here’s the back cover with all the screws revealed:
The screws are not of the same type either, so I ensured to remember their places:
Again, removing the cover after removing all the screws might not be straightforward: take inspiration from the linked video above! It took me some effort and a few attempts, but I finally made it! Here’s the removed cover and the internal of the laptop (well organized and neat, isn’t it?):
Now, let’s zoom in on the second SLOT:
You can see that it says NVME and SATA3. I haven’t tried with a SATA3, but, as I said, I had no problem with the Samsung NVME!
IMPORTANT: unplug the battery cable before continuing (at least, that’s what the LG video says). That’s easy: pull it gently.
Remove the screw from the second slot:
Insert the SSD (that’s easy):
And secure it with the screw:
Of course, now we have to reconnect the battery cable!
Let’s take a final look at the result:
OK! Let’s close the laptop: putting the cover back is easier than removing it, but you still have to ensure you close the cover correctly. Put the screws back and the rubber feet (that’s also easy because they are still sticky).
The moment of truth… will the computer recognize the added SSD? Let’s enter the BIOS and… suspense… 😀
I booted into Linux (sorry, I almost never use Windows, and, to be honest, I still haven’t checked whether Windows is happy with the new SSD) and used the KDE partition manager to create a new partition to make a few experiments:
Everything looks fine! In the meantime, I’ve also created another partition for virtual machines on the new SSD, which works like a charm! I haven’t checked whether it’s faster than the primary SSD, which comes with the laptop.
Assuming you use SSH keys protected with a passphrase, each time you use an SSH connection with the SSH key, you are prompted for the passphrase.
You can use ssh-agent and ssh-add.
First, start the agent:
1
eval$(ssh-agent)
Then, use ssh-add to add a specific key (see the documentation) or all the keys:
1
ssh-add
You are prompted for the passphrase, but then, the passphrase is remembered, and you are not asked anymore (unless the lifetime expires, by default, 1 hour).
Unfortunately, this holds only in the current terminal. It works for other applications started from that terminal. For example, if you start Visual Studio from that terminal and you access a Git repository with your SSH key, the passphrase is reused without prompting you. If you start another terminal or program using its launcher, you are prompted for the passphrase again; moreover, in such a situation, the passphrase is not remembered since you should rerun ssh-add.
Instead, I’d like to be prompted for the passphrase only the first time I use ssh; for the current desktop session, I don’t want to enter the passphrase again. Of course, if I reboot, I’m OK with re-entering the passphrase the first time I need it.
In GNOME, you can rely on its keyring to prompt you for the passphrase and store it for the current session or permanently. In KDE, you have a similar mechanism, which, however, has to be appropriately configured (that’s out of the scope of this post).
In Hyprland, you have to set up such mechanisms manually.
The Arch Wiki, as usual, documents an easy solution, which I’ll report here (I haven’t tried alternatives, but this one is pretty easy to set up).
Reboot to ensure the environment variable is set correctly and the service is started.
Try to use ssh, and you will be prompted for your passphrase. Try to use ssh again for that passphrase, and you should not be asked for the passphrase. Start a new terminal, use SSH again, even with Git, and you will not be asked for the passphrase. This also works for other programs that need SSH, for example, Visual Studio Code when accessing a Git repository or Unison when connecting through SSH.
From now on, you’ll be asked for the passphrase only the first time you use ssh from any program and never more for that session.
When I logged into the Plasma Wayland session with a brand-new user, the system automatically switched to 150% scaling. This is good because my LG GRAM 16 needs at least that scaling level.
Unlike my experiments last year, this is enough to have a nice-looking environment, and even GTK applications look great without blurring! For example, this is the EndeavourOS Welcome application (GTK-based):
Usually, a 150% scaling on this computer is not enough for my eyes, and I prefer 175%. I then configured the new scaling, pressed “Apply,” and everything was applied immediately: no logout was required (instead, on X11, this is usually required to have everything scaled correctly):
Touchpad gestures still work great, but they are still not configurable:
4 Finger Swipe Left –> Next Virtual Desktop.
4 Finger Swipe Right –> Previous Virtual Desktop.
4 Finger Swipe Up –> Desktop Grid.
4 Finger Swipe Down –> Available Window Grid.
Context menus of desktop and other Plasma widgets (e.g., the applications menu) in the presence of fractional scaling look nicer in Wayland than in X11!
For example, in X11, menu entries look too crowded:
While on Wayland, they look nice (the fonts also look better on Wayland):
Concerning GTK applications, my main one is Eclipse. As it was happening when I tried Plasma Wayland last year, the Eclipse splash screen has the title bar and window buttons, which looks strange:
Besides that, Eclipse looks nice:
Note, however, that there are still a few bad things: the Eclipse icon is not recognized, and you get a generic Wayland icon. This happens also in GNOME Wayland. There’s an open bug, but still no solution. Moreover, things like hover pop-ups are dismissed too soon in Wayland.
One last bad thing I noted is that the login manager SDDM does not remember the X11 or Wayland session per user: it just uses the last used session globally. I’m pretty sure it wasn’t like that in the past. I don’t know, though, whether SDDM or Plasma is to blame here 😉
I guess it’s time to use KDE Plasma with Wayland daily and see how it goes. 🙂
Let’s restart Hyprland (such a change in the configuration file needs a restart), e.g., with the default shortcut SUPER + M, we exit Hyprland, and then we can log back in. When a program needs to elevate its privileges, we get the KDE dialog. For example, if we use the EndeavourOS Welcome App to update the mirrors, we get the dialog as soon as the mirror file must be saved:
The same happens if we run from a terminal a “systemctl” command that needs superuser privileges:
Having the authentication dialog tiled as the other windows is not ideal. So let’s create a Window rule in the Hyprland configuration to make it floating:
TIP: to know the values for “class”, you can use “hyprctl clients” when the desired application is running and inspect its output by looking for the “class:” part.
Keyboard shortcuts
Hyprland is about using keyboard shortcuts a lot. You might want to take some time to get familiar with the main keyboard shortcuts for launching and closing (look at the configuration file). Change them as you see fit if you don’t like the default ones.
These are the default ones as set in the example configuration we started with:
1
2
3
4
5
6
7
8
9
10
11
12
# See https://wiki.hyprland.org/Configuring/Keywords/ for more
$mainMod=SUPER
# Example binds, see https://wiki.hyprland.org/Configuring/Binds/ for more
bind=$mainMod,Q,exec,kitty
bind=$mainMod,C,killactive,
bind=$mainMod,M,exit,
bind=$mainMod,E,exec,nemo
bind=$mainMod,V,togglefloating,
bind=$mainMod,R,exec,wofi--show drun
bind=$mainMod,P,pseudo,# dwindle
bind=$mainMod,J,togglesplit,# dwindle
I prefer these (note that SUPER+Q now has an entirely different behavior):
1
2
3
4
5
6
7
8
9
bind=$mainMod SHIFT,R,exec,hyprctl reload
bind=$mainMod,D,exec,wofi--show drun
bind=$mainMod SHIFT,Return,exec,nemo
bind=$mainMod SHIFT,F,togglefloating
bind=$mainMod,F,fullscreen
bind=$mainMod,Q,killactive,
bind=$mainMod,Return,exec,kitty
bind=$mainMod,P,pseudo,# dwindle
bind=$mainMod,J,togglesplit,# dwindle
Some additional shortcuts might be helpful as well, such as the following (“grouping” has to do with tabbed windows):
1
2
3
4
5
6
7
8
# For grouping (tabbed windows)
bind=$mainMod,G,togglegroup
bind=$mainMod,tab,changegroupactive,f
bind=$mainMod SHIFT,tab,changegroupactive,b
# For workspaces
bind=ALT,tab,workspace,m+1
bind=ALT SHIFT,tab,workspace,m-1
And for moving tiled windows:
1
2
3
4
5
# Move
bind=$mainMod CTRL,H,movewindow,l
bind=$mainMod CTRL,L,movewindow,r
bind=$mainMod CTRL,K,movewindow,u
bind=$mainMod CTRL,J,movewindow,d
Mouse gestures
Hyprland provides mouse gestures (swipe) for switching among workspaces. This is not enabled by default, but it’s easy to do: change the existing “gestures” section as follows:
1
2
3
4
5
gestures{
# See https://wiki.hyprland.org/Configuring/Variables/ for more
workspace_swipe=true
workspace_swipe_fingers=3
}
Screenshots
Let’s configure the system to take screenshots.
First, we install “grim” (A screenshot utility for Wayland)
1
sudo pacman-Sgrim
Let’s also install an image viewer, like “Eye of Gnome”:
1
sudo pacman-Seog
You can try to run “grim” from a terminal to see how it works: by default, it takes a screenshot of the whole screen and save the corresponding images with names containing date and time in the “Pictures” folder. For example, after running “grim” twice, I get the following:
What if we want to take a screenshot of a region? We need another program, “slurp” (Select a region in a Wayland compositor)
1
sudo pacman-Sslurp
And we configure a few key bindings (note the last one, which takes a screenshot of the currently active window: this requires several commands to get the active window through Hyprland and then compute a few screen coordinates to pass to “grim”):
How to set the screen’s brightness and volume through the corresponding keys?
First, install “brightnessctl”:
1
sudo pacman-Sbrightnessctl
You can get the current brightness by simply running the program (or with “get” or “-m”) and changing it with the “set” and the value (e.g., increase/decrease by percentage). For example:
1
2
3
brightnessctl set10%+
brightnessctl set10%-
So, we need to bind the appropriate special keys to such commands:
Now, when we press SUPER + L, the screen is locked (swaylock can be configured with colors and the like, but I won’t discuss that). You have to type your password: when you start doing that, you’ll see a circle with some parts changing. If you get the password wrong, swaylock will notify you.
The “exec-once” (remember, you need to restart Hyprland for that) will lock the screen after 300 seconds, but it will also turn it off using a “hyprctl” dispatch command. Note that when that happens, you need to press a key or move the mouse, and the instruction above instructs the system to turn the screen back on. Of course, then you’ll have to type your password.
That’s all for now! Stay tuned for more posts about Hyprland 🙂
In the past few months, I’ve heard (i.e., read articles and seen videos) many good things about the Wayland compositor Hyprland. I decided to try it, and I’ve been using it for almost one month as my daily driver. I’m still not into “tiling” that much, but in Hyprland, you can also switch to classic “stack” window management. I like Hyprland; it feels fast and reactive (also on a PineBook Pro; I’ll blog about Hyprland on a PineBook Pro in the future).
By the way, if you don’t already know:
Hyprland is a dynamic tiling Wayland compositor based on wlroots that doesn’t sacrifice on its looks. It supports multiple layouts, fancy effects, has a very flexible IPC model allowing for a lot of customization, a powerful plugin system and more.
This post is the first of a few articles showing how to install, configure and use Hyprland and additional tools. You can find many GitHub repositories with installation scripts and configuration files for Hyprland, but you end up with the configurations of those repositories, probably without understanding the basic details of Hyprland. I found starting from scratch (following the Hyprland wiki) much more helpful, taking inspiration from some of the above-mentioned GitHub repositories.
By the way, most Hyprland configurations you find on GitHub are primarily about “ricing” (i.e., heavy aesthetic customizations of the desktop). While I love good-looking desktops, I won’t blog about aesthetic customizations much. I’ll focus mostly on configurations and tools for usability.
This first post is only about getting started and having a usable environment with minimal helpful tools: there will be follow-up posts for installing other tools (like a bar and notification system) and configuring other programs (actually, I have already blogged about Variety in Hyprland).
Moreover, all these posts are about Hyprland in Arch Linux since that’s the only OS where I experimented with Hyprland. In particular, I’m using EndeavourOS.
First, install EndeavourOS without a desktop environment (when you get to the installer’s part, where you have to select a desktop environment).
I will use the AUR helper “yay”, which is already installed in EndeavourOS. On Arch, you’ll have to install it yourself, e.g., with the following commands:
As suggested, let’s install the terminal “Kitty” (the default Hyprland configuration has a shortcut to run that).
1
sudo pacman-Skitty
Of course, later, you can also install another terminal.
Now, you can execute “Hyprland” in your tty. (Remember, I haven’t installed any desktop environment or a login manager).
Note for virtual machines: If you test this in a virtual machine, ensure that 3D is enabled. Moreover, it’s crucial to start Hyprland with the following environment variables so that the mouse is usable; please, remember that the experience in a virtual machine will not be optimal anyway:
When Hyprland starts, you see a warning and a few pieces of information:
To make the warning go away, we edit the generated default configuration file (use either “vi” or “nano” text editors that are already installed in EndeavourOS). To do that, we must start a terminal: by default, the keyboard shortcut is “SUPER + Q” (as shown in the yellow warning):
Now we can edit the file .config/hypr/hyprland.conf and remove the following line:
1
autogenerated=1# remove this line to remove the warning
Save the file, and the warning will go away. In fact, one of the cool features of Hyprland is that it automatically applies changes to that file.
Let’s change the configuration file further. By default, the configuration uses a US keyboard layout. I had to change it to use the Italian layout: Edit that file and change the following part accordingly (in my case, I have an Italian keyboard):
1
2
3
4
...
input{
kb_layout=it
...
Save the file, and the new keyboard layout will be immediately set.
You might want to install “neofetch” and run it in a terminal (in this example, I’m running inside a KVM virtual machine):
The default configuration uses the shortcut SUPER + E to start the file manager “Dolphin”, which is not installed by default. You could install it. Here, I’m doing something different: Let’s install the file manager “nemo”:
1
sudo pacman-Snemo
and change the line
1
bind=$mainMod,E,exec,dolphin
into
1
bind=$mainMod,E,exec,nemo
Let’s save the file, press SUPER + E, and Nemo appears (tiled automatically)
Let’s install the application launcher “wofi” (personally, I prefer “rofi”, but I’ll blog about that in the future):
1
sudo pacman-Swofi
Wofi is already configured with the following keyboard shortcut:
1
bind=$mainMod,R,exec,wofi--show drun
For example, let’s use SUPER + R and run Firefox (already installed in EndeavourOS) using Wofi: just start typing “fir” until it appears in the list, move the cursor down to select it, and press ENTER (or keep on typing the other letters til “firefox” is the only choice).
Let’s exploit the blur effects of Hyprland: let’s modify the Kitty configuration file (create it if it doesn’t exist) ~/.config/kitty/kitty.conf by adding this line:
1
background_opacity0.5
Save it and start another instance of Kitty and enjoy the blur effect with the default Hyprland background:
If “0.5” is too much transparency, make the value a bit bigger.
Let’s make Nemo transparent as well with an Hyprland window rule. By default, Nemo is not transparent:
Let’s modify the Hyprland configuration file by adding this line:
1
windowrulev2=opacity0.80.8,class:^(nemo)$
Save and restart Nemo, which is now transparent:
The two values in “opacity” set the opacity for the window when it’s focused and not, respectively. By changing the above line as follows:
1
windowrulev2=opacity0.90.6,class:^(nemo)$
The Nemo window will be less transparent when active and more transparent when not focused.
Monitor(s) configurations are specified in the Hyprland configuration and are applied on the fly as soon as you save the configuration file. This is the default configuration:
1
2
# See https://wiki.hyprland.org/Configuring/Monitors/
monitor=,preferred,auto,auto
The last value is the scale value. Try to change it to “1.5” or “1.75”, save, and see the scaling automatically applied.
Note that, by default, when running on a real computer (not a virtual machine), Hyprland already scales the display for high resolutions (e.g., it sets it to “1.5” by default).
Running from a Display Manager
The default installation already created a file in the appropriate folder to let SDDM start the Hyprland session.
1
2
3
4
5
6
$cat/usr/share/wayland-sessions/hyprland.desktop
[Desktop Entry]
Name=Hyprland
Comment=An intelligent dynamic tiling Wayland compositor
Exec=Hyprland
Type=Application
Let’s install the AUR package “sddm-git” (we need the Git version to avoid a bug that has been fixed but not in the current release; when reading this post, the official package might have already been fixed) with yay:
1
yay-Ssddm-git
Then, we enable the service at boot:
1
sudo systemctl enable sddm
If we want to start it without rebooting, the first time we run:
1
sudo systemctl start sddm
And now you can enter Hyprland from here.
If you’re running inside a virtual machine, you lose the environment variables we saw above: “WLR_NO_HARDWARE_CURSORS=1 WLR_RENDERER_ALLOW_SOFTWARE=1”. To restore them, you must modify the “/usr/share/wayland-sessions/hyprland.desktop” accordingly, in particular, the “Exec” line:
This method consists of a two-step installation process:
use the standard EndeavourOS ISO, booting that from a PC, to install the installation image on an external device (in this example, I will use a USB stick);
then boot the PineBook Pro with the created USB stick and use Calamares to finalize the installation on the very same device you booted from.
Note that I will install EndeavourOS for Arm on an external device, NOT on the eMMC of the PineBook Pro. In this article, I’ll leave a few hints on how to do that on the internal eMMC.
First step
On a standard PC, boot the EndeavourOS ISO (in this example, I’m using the Cassini 2023-03 R2):
After adjusting the keyboard layout and connecting to the Internet, choose “EndeavourOS ARM Image Installer”.
As noted, you need first to insert a USB stick. If you plan to install it on the PineBook Pro’s internal eMMC, you must extract it and place it in a USB adapter. Then, choose “Strat ARM Installer”. That is a textual installation procedure so the installer will open a terminal in full-screen mode.
After pressing OK, you must select the ARM computer (in this case, “PineBook Pro”):
Concerning the file system, in all my experiments, BTRFS has never worked: when rebooting the USB stick (see later), the screen stays blank forever after selecting the boot media. So, the only working solution is EXT4:
Then, you have to write the device where you want to install the installer; the dialog shows all the devices, and you must write the main path of the device, NOT of a possibly existing single partition (in this case, it’s “/dev/sdb”):
Small note: unfortunately, the colors of this textual installer are not ideal 😉
Then, the procedure will prepare the device and download an archive from the Internet for the image to put on the USB stick (it’s a big image, so be patient):
Ultimately, it tells you about the temporary username and password for the installer copied on the USB. It also suggests unmounting the USB with a file manager. In the live environment, you use Thunar to unmount the USB stick. You can recognize the mounted USB stick to unmount because it should show two mounted partitions (the first one is about 128 Mb):
Umounting one of them will also unmount the other one.
Second step
It’s time to boot the PineBook Pro with the UBS stick we created with the abovementioned process. If, in the previous procedure, you created the installer on the eMMC (connected with a USB adapter), you should put the eMMC inside the PineBook Pro.
When the PineBook Pro starts, you should find a way to boot from the USB stick. If you’ve always used the Manjaro installation that comes with the PineBook Pro, you have U-Boot as the bootloader (see my previous blog post for a screenshot of U-Boot booting from the USB stick). If you’re lucky, it should give precedence to the USB stick (I’ve read that this is not always the case, depending on the version of the installed U-Boot). In this example, I have Tow-Boot as the bootloader, so when you see the message telling you to press ESCAPE (or Ctrl-C) to enter the boot menu, please do so:
And then, select the USB as the boot media (of course, if you installed the image on an SD, choose accordingly):
After some textual logs, you should get to the graphical environment for the actual installation. The Window Manager is OpenBox, so, differently from the standard EndeavourOS installer for PC, you don’t have a fully-fledged Desktop Environment (Xfce):
Now, you can choose whether to install an “Official” (e.g., KDE or GNOME) or a “Community” edition (e.g., Sway).
Remember: the installation will be performed on the same media you have just booted. In this example, it’s a USB stick. Again, if you want to install EndeavourOS on the internal eMMC, you first need to extract the eMMC, put it on a USB adapter, do the first procedure described above, put the eMMC back into the PineBook Pro, and start the installation from the eMMC.
As you can see from the screenshots above, there’s no section for partitioning the disk. The partitions have already been created during the first procedure. This installation procedure only finalizes the installation.
I’ve tried both KDE and GNOME.
Enjoy your EndeavourOS installation 🙂
If you like it on a USB stick (remember, it should be a fast USB), you might want to install it on the eMMC (see the notes in this blog post about that). I have already done that, and it works much better than the original Manjaro!
This blog post will describe my Ansible role for installing “Oh My Zsh” and several command line programs. The role also installs the starship prompt or the p10k theme. As for the other roles I’ve blogged about, this one is tested with Molecule and Docker and can be developed with Gitpod (see the linked posts above). In particular, it is tested in Arch, Ubuntu, and Fedora.
This role is for my personal installation and configuration and is not meant to be reusable.
Besides “zsh” and “git” (which are needed for installing other things, and, in general, I need it daily), this installs several command line tools, like ripgrep, procs, dust, exa, bat, zoxide. Note that, depending on the operating system, these tools must be installed differently (e.g., from the package manager or by downloading a binary distribution). In a few cases, the package names differ depending on the operating system. In such cases, the default names are defined in “vars/main.yml” and properly overridden depending on the operating system:
YAML
1
2
3
4
5
6
# vars file for oh_my_zsh
powerlinefonts: powerline-fonts
fdfind: fd-find
dustversion: v0.8.3
procsversion: v0.13.3
with_starship: true
The task also installs a few fonts (nerd fonts, with emoji, or with icon characters), which are needed because “starship” and “p10k” need a few icon characters; the same holds for other tools like exa.
“Oh My Zsh” is installed by cloning its Git repository; the same holds for some external plugins. The task also sets “zsh” as the default shell for the current user.
Finally, depending on the variable with_starship, which defaults to true, it installs the starship prompt or the p10k theme. These are handled in the corresponding included files “starship.yml” and “p10k.yml”, respectively.
YAML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
---
# tasks file for starship
- name: Install starship (cross-shell prompt) as a package
become: true
ansible.builtin.package:
state: present
name: starship
when: ansible_os_family == 'Archlinux'
- name: Install curl (for starship installation)
become: true
ansible.builtin.package:
state: present
name: curl
when: ansible_os_family != 'Archlinux'
- name: Get starship install script
ansible.builtin.get_url:
url: https://starship.rs/install.sh
dest: /tmp/starship_install.sh
mode: '0755'
register: starship_installation_script
when: ansible_os_family != 'Archlinux'
- name: Install starship with installation script
become: true
ansible.builtin.shell:
cmd: /tmp/starship_install.sh --yes
executable: /bin/sh
when: ansible_os_family != 'Archlinux' and starship_installation_script.changed
# if the previous task hasn't changed, the shell script is already there
Note that both files copy the corresponding template for “.zshrc” (depending on starship or p10k, the contents of “.zshrc” are slightly different). For “p10k”, it also copies my theme configuration”; for “starship”, I’m OK with the default prompt. The copied “.zshrc” contains several “aliases” for the command line programs installed by this role (e.g., “ls” is aliased to “exa” commands).
Concerning Molecule, I have several scenarios. As I said, I tested this role in Arch, Ubuntu, and Fedora, so I have a scenario for each operating system. In such cases, I test the “starship” installation and verify that the tools that differ for their installations in different operating systems are installed correctly. This is the “verify.yml” (remember that this installs “starship” and NOT “p10k”, so it ensures that only the former is installed):
- name: Assert ~/.p10k.zsh is NOT present in this scenario
ansible.builtin.assert:
that: "notresult.stat.exists"
Concerning “p10k,” I have a separate scenario with a different “verify.yml” (I test this only on Arch since “starship” and “p10k” installations and configurations are the same in all three operating systems):
YAML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
---
# This is an example playbook to execute Ansible tests.
However, this “verify.yml” could also be used for the other operating systems since it performs the same verifications concerning installed programs. It differs only for the final part.
Of course, this is tested on GitHub Actions and can be developed directly on the web IDE Gitpod.
I hope you find this post useful for inspiration on how to use Ansible to automatize your Linux installations 🙂
With TLP, the procedure is easier and more automatic.
First, you must install tlp (remember that tlp conflicts with power-profiles-daemon, so you have to disable the latter first or uninstall it). In Arch-based distros:
1
sudo pacman-Stlp tlp-rdw
Ensure that the tlp service is enabled on boot and the first time you should start it (“sudo systemctl start tlp”).
By running “sudo tlp-stat”, you should see near the end this line:
1
2
3
4
5
6
7
+++ Battery Care
Plugin: lg
Supported features: charge threshold
Driver usage:
* vendor (lg_laptop) = active (charge threshold)
Parameter value range:
* STOP_CHARGE_THRESH_BAT0: 80(on), 100(off) -- battery care limit
Edit the file “/etc/tlp.conf” and uncomment the following lines (note there’s one also for the start of charging, but that option doesn’t seem to be supported in this laptop):
1
2
START_CHARGE_THRESH_BAT0=75
STOP_CHARGE_THRESH_BAT0=80
Restart the service (“sudo systemctl restart tlp.service”), and it should be already active (run “tlp-stat” again):
That’s all. This will persist on reboot. However, this will not persist if you hibernate and return from hibernation (unless you restart the tlp service as shown above).
In this blog post, I’m showing how I customize KDE on that installation (thus, it is similar to this other one for GNOME).
I’m not using Wayland because I still don’t find it usable in Plasma. Indeed, I haven’t even installed the Wayland session: I’m using X11.
First of all, the default screen resolution of KDE is too tiny for my eyes. Thus, I set 150% (fractional) scaling:
After that, you have to log out and log in to see the setting in effect.
I also enable “Tap-to-click” in the “Touchpad” settings.
Then, I set “Ctrl+Alt+T” as a shortcut for opening the terminal (Konsole). Actually, the shortcut is already configured in the “Custom Shortcuts”, but it’s not enabled by default in this distribution. It’s just a matter of selecting the corresponding checkbox (the “Examples” checkbox must be selected first to enable the other checkbox):
Then, I install an AUR helper. I like “yay,” so I first installed the needed dependencies:
1
sudo pacman-S--needed git base-devel
And then
1
2
3
4
5
mkdir -p ~/git
cd ~/git
git clone https://aur.archlinux.org/yay.git
cd yay
makepkg -si
I install, by using “yay”, the “touchegg” program for touchpad gestures. (Plasma Wayland already provides touchpad gestures, but I prefer to use the X11 session, as I said above). For ARM, we need to install the AUR package:
1
yay-Stouchegg
You will get this warning, but proceed anyway: it compiles and works fine:
1
2
3
4
:: (1/1) Parsing SRCINFO: touchegg
-> The following packages are not compatible with your architecture:
touchegg
:: Try to build them anyway? [Y/n]
I customize touchegg touchpad gestures for KDE by creating the file “~/.config/touchegg/touchegg.conf” with the following contents:
XHTML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
<touchégg>
<settings>
<!--
Delay, in milliseconds, since the gesture starts before the animation is displayed.
Default: 150ms if this property is not set.
Example: Use the MAXIMIZE_RESTORE_WINDOW action. You will notice that no animation is
displayed if you complete the action quick enough. This property configures that time.
-->
<property name="animation_delay">150</property>
<!--
Percentage of the gesture to be completed to apply the action. Set to 0 to execute actions unconditionally.
Default: 20% if this property is not set.
Example: Use the MAXIMIZE_RESTORE_WINDOW action. You will notice that, even if the
animation is displayed, the action is not executed if you did not move your fingers far
enough. This property configures the percentage of the gesture that must be reached to
<!-- Change KP_Right to KP_Left if you prefer the other direction -->
<gesture type="SWIPE"fingers="4"direction="LEFT">
<action type="SEND_KEYS">
<repeat>false</repeat>
<modifiers>Alt_L</modifiers>
<keys>KP_Right</keys>
<on>begin</on>
</action>
</gesture>
<gesture type="PINCH"fingers="4"direction="IN">
<action type="SEND_KEYS">
<repeat>true</repeat>
<modifiers>Control_L</modifiers>
<keys>Shift_L+Tab</keys>
<decreaseKeys>Shift_L+Tab</decreaseKeys>
<on>begin</on>
</action>
</gesture>
<gesture type="PINCH"fingers="4"direction="OUT">
<action type="SEND_KEYS">
<repeat>true</repeat>
<modifiers>Control_L</modifiers>
<keys>Tab</keys>
<decreaseKeys>Shift_L+Tab</decreaseKeys>
<on>begin</on>
</action>
</gesture>
</application>
</touchégg>
In particular, note the 3-finger gestures (for the “Expose” effect, hide all windows, switch workspace, etc.).
Let’s start “touchegg” and verify that gestures work
1
touchegg
And then let’s enable it so that it automatically starts on the subsequent boots:
1
sudo systemctl enable touchegg.service
Let’s move on to ZSH, which I prefer as a shell:
1
sudo pacman-Szsh
Since I’m going to install “Oh My Zsh” and other Zsh plugins, I install these fonts (remember from the previous post that I had already installed “noto-fonts” and “noto-fonts-emoji”) and finder tool (“curl” is required for the installation of “Oh My Zsh”):
1
sudo pacman-Spowerline-fonts fzf curl
Let’s install “Oh My Zsh” by running the following command as documented on its website:
Once saved, you have to start a new terminal with zsh to see the plugins in action (remember that, until you log out and log in, the default shell is still BASH, so you might have to run “zsh” manually to switch to ZSH in the currently logged session).
Besides the syntax highlighting for commands, you have completion after “cd” (press TAB), excellent command history (with Ctrl+R), suggestions, etc.
Let’s switch to the “Starship” prompt. Let’s run the documented installation program:
1
curl-sS https://starship.rs/install.sh | sh
Now, let’s edit the ~/.zshrc file again; we comment the line starting with “ZSH_THEME,” and we add to the end of the file:
1
eval"$(starship init zsh)"
Opening another ZSH shell, we should see the fantastic Starship prompt in action, e.g.,
To quickly search for file names from the command line, I install “locate”, enable its periodic indexing and run the indexing once the first time (if you’re on a BTRFS file system, you might want to have a look at this older post of mine):
1
2
3
4
5
sudo pacman-Splocate
sudo systemctl enable plocate-updatedb.timer
sudo updatedb
Then, you should be able to look for files with the command “locate” quickly.
Gnome uses “Baloo” for file indexing and searching, e.g., from “KRunner” (Alt+Space) or the application launcher (Alt+F1 or simply Meta). I like it, and it quickly keeps the index up to date. However, by default, baloo also indexes the file contents, which uses too many resources, so I disable the content indexing feature. I blogged about configuring baloo in another post.
Speaking about KRunner, I find it extremely slow on this laptop; especially the first time you run it, it might take a few seconds to show up. I often use it to search for files or programs, and I need such a mechanism to be fast. I found that the application launcher is instead fast to start (Meta key). However, when you start typing to search, the results are all mixed: applications, files, and settings are all together, and it might not be easy to find what you need:
For this reason, I right-click on the KDE icon and select the “Alternative” “Application Menu”:
This launcher has a valuable feature to categorize the search results. For example, with the exact search string as above, I get results clearly separated:
I also use the “yakuake” drop-down terminal a lot:
1
sudo pacman-Syakuake
I run it once (it’s enabled by default by pressing “F12”), and it will start automatically upon logging in.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checkbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checkbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Functional cookies help to perform certain functionalities like sharing the content of the website on social media platforms, collect feedbacks, and other third-party features.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.